Für den aktuellen Sammelband Moderne Personalpolitik in Handel und Vertrieb habe ich mir die Frage gestellt, wie sich Karriere-Seiten von Handelsunternehmen hinsichtlich ihres Employer Brandings semi-automatisiert untersuchen lassen. Zielfragen sind hier auf der textuellen und auf der bildlichen Ebene angesiedelt: Welche Aussagen werden getroffen? Wie unterscheiden sich die Texte der einzelnen Seiten? Welche Bilder werden auf den Seiten genutzt? Wie unterscheiden sich die Bilder zwischen den Seiten? Im folgenden beschreibe ich kurz einen ersten Ansatz, mit dem sich diese Fragen beantworten lassen. Einige Passagen im R-Code sind sicherlich noch optimierungsfähig. Falls jemand Vorschläge hat, freue ich mich auf Kommentare.
Auswahl von Daten
Für diesen Post und für das Sammelbandkapitel möchte ich mich auf die Karriere-Seiten der größten Handelsunternehmen in Deutschland fokussieren. Zur Hilfe dient der Deloitte Report “Global Powers of Retailing 2018”. Dieser enthält die TOP 250 Handelsunternehmen der Welt.
Ausgewählt werden Unternehmen mit Sitz in Deutschland.
Auswahl:
- Schwarz Gruppe
- Aldi Gruppe
- Metro AG
- Edeka Gruppe
- Rewe Gruppe
- Otto
- Tengelmann Warenhandelsgesellschaft
- dm-drogerie markt GmbH
- Dirk Rossmann GmbH
- Globus Holding GmbH
- Bauhaus GmbH
- Deichmann SE
- Müller Holding
- McKesson Europe AG
- HORNBACH Baumarkt
- Zalando SE
- Intersport Deutschland SE
In einem nächsten Schritt werden die zugehörigen Handelunternehmen (Tochtermarken) identifiziert. Ausgewählt wurden nur solche Unternehmen, die auch im niedergelassenen Filialhandel tätig sind.
Dann werden die Webseiten der identifizierten Unternehmen besucht und Karriere-Seiten identifiziert, die ein Employer-Branding enthalten. In der Regel sind dies die allgemeinen Karriere-Seiten, die Informationen zu “Das Unternehmen als Arbeitgeber”, “Arbeiten beim Unternehmen”, “Warum hier Arbeiten?” oder “Unser Angebot” enthalten. Links zu archivierten Seiten werden für die Reproduzierbarkeit identifiziert (falls in der Wayback Machine archiviert). Karriereseiten von Verbundunternehmen wurden nur aufgenommen, wenn sie sich vom Hauptunternehmen unterschieden.
Hier der daraus resultierende Datensatz, der hier runtergeladen werden kann:
library(tidyverse)
company_list <- read.csv2("employer_branding_company_list.csv")
company_list$Archiv.URL <- as.character(company_list$Archiv.URL)
company_list$URL.Branding.Seite <- as.character(company_list$URL.Branding.Seite)
company_list$ID_Einzelunternehmen <- as.character(company_list$ID_Einzelunternehmen)
company_list$Einzelunternehmen <- as.character(company_list$Einzelunternehmen)
knitr::kable(company_list, format = "markdown")
| ID_Hauptunternehmen | Hauptunternehmen | ID_Einzelunternehmen | Einzelunternehmen | URL.Branding.Seite | Archiv.URL |
|---|---|---|---|---|---|
| 1 | Schwarz Gruppe | 1.1 | Lidl | https://jobs.lidl.de/de/das-sind-wir-2429.htm | https://web.archive.org/web/20171029214432/https://jobs.lidl.de/de/das-sind-wir-2429.htm |
| 1 | Schwarz Gruppe | 1.2 | Kaufland | https://karriere.kaufland.de/kaufland-entdecken/ueber-uns/wer-wir-sind.html | https://karriere.kaufland.de/kaufland-entdecken/ueber-uns/wer-wir-sind.html |
| 2 | Aldi Gruppe | 2.1 | Aldi Nord | https://www.aldi-nord.de/karriere/ | https://web.archive.org/web/20180301025907/https://www.aldi-nord.de/karriere/ |
| 2 | Aldi Gruppe | 2.2 | Aldi Süd | https://karriere.aldi-sued.de/de/Wir-als-Arbeitgeber/Warum-zu-ALDI-S%C3%9CD | https://karriere.aldi-sued.de/de/Wir-als-Arbeitgeber/Warum-zu-ALDI-S%C3%9CD |
| 3 | Metro AG | 3.1 | METRO Cash & Carry | https://www.metro-cc.com/de-DE/karriere/warum-metro-cash-and-carry | https://www.metro-cc.com/de-DE/karriere/warum-metro-cash-and-carry |
| 3 | Metro AG | 3.2 | Real | https://www.real.de/unternehmen/jobs-karriere/arbeiten-bei-real/ | https://www.real.de/unternehmen/jobs-karriere/arbeiten-bei-real/ |
| 4 | Edeka Gruppe | 4.1 | Edeka-Verbund | http://www.edeka-verbund.de/Unternehmen/de/karriere/studierendeundabsolventen/was_wir_ihnen_bieten_2/was_wir_ihnen_bieten_3.jsp | https://web.archive.org/web/20171009164658/http://www.edeka-verbund.de/Unternehmen/de/karriere/studierendeundabsolventen/was_wir_ihnen_bieten_2/was_wir_ihnen_bieten_3.jsp |
| 4 | Edeka Gruppe | 4.2 | Diska | http://www.diska.de/karriere/ | https://web.archive.org/web/20171009161045/http://www.diska.de/karriere/ |
| 4 | Edeka Gruppe | 4.3 | Treff3000 | https://www.treff3000.de/html/liste/ausbildung_2018.html | https://www.treff3000.de/html/liste/ausbildung_2018.html |
| 4 | Edeka Gruppe | 4.4 | NP.Discount | https://www.np.de/unternehmen/ | https://web.archive.org/web/20180127083854/https://www.np.de/unternehmen/ |
| 4 | Edeka Gruppe | 4.5 | Netto Marken-Discount | https://www.netto-online.de/karriere/Warum-zu-Netto.chtm | https://www.netto-online.de/karriere/Warum-zu-Netto.chtm |
| 5 | Rewe Gruppe | 5.1 | Rewe | https://karriere.rewe.de/arbeiten-bei-rewe/unsere-arbeitswelt/leistungen.html | https://karriere.rewe.de/arbeiten-bei-rewe/unsere-arbeitswelt/leistungen.html |
| 5 | Rewe Gruppe | 5.2 | Penny | http://karriere.penny.de/das-ist-jetzt-dein-job/vorteile/ | https://web.archive.org/web/20171031150735/http://karriere.penny.de/das-ist-jetzt-dein-job/vorteile/ |
| 5 | Rewe Gruppe | 5.3 | Nahkauf | https://www.nahkauf.de/kaufleute-gesucht/ | https://web.archive.org/web/20170928055928/http://www2.nahkauf.de:80/kaufleute-gesucht/ |
| 5 | Rewe Gruppe | 5.4 | Toom | https://karriere.toom.de/komm-in-unser-team | https://karriere.toom.de/komm-in-unser-team |
| 6 | Otto Gruppe | 6.1 | Lascana | ||
| 6 | Otto Gruppe | 6.2 | Manufactum | https://www.manufactum.de/manufactum-stellenangebote-c-37/ | https://www.manufactum.de/manufactum-stellenangebote-c-37/ |
| 6 | Otto Gruppe | 6.3 | myToys | https://mytoysgroup.jobs/ | https://web.archive.org/web/20171016113744/https://mytoysgroup.jobs/ |
| 6 | Otto Gruppe | 6.4 | BonPrix | https://www.bonprix.de/corporate/karriere/arbeitswelt/ | https://web.archive.org/web/20170706033530/https://www.bonprix.de/corporate/karriere/arbeitswelt/ |
| 6 | Otto Gruppe | 6.5 | Frankonia | https://www.frankonia.de/service/karriere-bei-frankonia.html | https://web.archive.org/web/20160817164139/http://www.frankonia.de/service/karriere-bei-frankonia.html |
| 6 | Otto Gruppe | 6.6 | SportScheck | https://www.sportscheck.com/unternehmen/jobs/ausbildung-bei-sportscheck/ | https://www.sportscheck.com/unternehmen/jobs/ausbildung-bei-sportscheck/ |
| 7 | Tengelmann Warenhandelsgesellschaft | 7.1 | KiK | http://www.kik-textilien.com/unternehmen/karriere/ | http://www.kik-textilien.com/unternehmen/karriere/ |
| 7 | Tengelmann Warenhandelsgesellschaft | 7.2 | OBI | https://www.obi.de/karriere/warum-obi/ | https://web.archive.org/web/20170916230628/https://www.obi.de/karriere/warum-obi/ |
| 8 | dm-drogerie markt GmbH | 8.1 | dm | https://www.dm.de/arbeiten-und-lernen/arbeiten-bei-dm/ | https://www.dm.de/arbeiten-und-lernen/arbeiten-bei-dm/ |
| 9 | Dirk Rossmann GmbH | 9.1 | Rossmann | https://www.rossmann.de/unternehmen/karriere/arbeiten-bei-rossmann.html | https://web.archive.org/web/20170611153136/https://www.rossmann.de/unternehmen/karriere/arbeiten-bei-rossmann.html |
| 10 | Globus Holding GmbH | 10.1 | Globus | http://www.globus.de/de/unternehmen/arbeitenbeiglobus/arbeitenbeiglobus.html | https://web.archive.org/web/20171019154754/http://www.globus.de:80/de/unternehmen/arbeitenbeiglobus/arbeitenbeiglobus.html |
| 11 | BAUHAUS GmbH | 11.1 | BAUHAUS | https://www.bauhaus.info/arbeitgeber-bauhaus | https://www.bauhaus.info/arbeitgeber-bauhaus |
| 12 | Deichmann SE | 12.1 | Deichmann | http://www.deichmann-karriere.de/arbeitgeber/ | http://www.deichmann-karriere.de/arbeitgeber/ |
| 13 | Müller Holding | 13.1 | Müller | https://www.mueller.de/unternehmen/karriere/arbeiten-bei-mueller/ | https://www.mueller.de/unternehmen/karriere/arbeiten-bei-mueller/ |
| 14 | McKesson Europe AG | 14.1 | gesundleben Apotheken | ||
| 15 | HORNBACH Baumarkt | 15.1 | Hornbach | https://jobs.hornbach.com/Germany/content/Arbeiten-bei-HORNBACH/?locale=de_DE | https://web.archive.org/web/20170709011417/https://jobs.hornbach.com/Germany/content/Arbeiten-bei-HORNBACH/?locale=de_DE |
| 16 | Zalando SE | 16.1 | Zalando | https://jobs.zalando.com/de/culture/ | https://web.archive.org/web/20170730015257/https://jobs.zalando.com/de/culture/ |
| 17 | Intersport Deutschland SE | 17.1 | INTERSPORT | https://www.intersport.de/unternehmen/karriere/ | https://www.intersport.de/unternehmen/karriere/ |
Erstellen des Corpus
Die identifizierten Webseiten wurden heruntergeladen und in Text-Dokumente umgewandelt. Der komplette Korpus im Text-Format kann hier heruntergeladen werden. Anschließend wurden sie in einen Text-Korpus überführt und bearbeitet. Zur Standard-Bearbeitung gehörte das Entfernen von überflüssigen Leerzeichen, die Transformation in Kleinbuchstaben und das Entfernen von Stopwörtern.
library(tm)
# Korpus laden
web_corpus <- VCorpus(DirSource(directory = "webpages/", encoding = "UTF-8",
mode = "text"))
# Korpus bereinigen
web_corpus <- tm_map(web_corpus, stripWhitespace)
web_corpus <- tm_map(web_corpus, content_transformer(tolower))
web_corpus <- tm_map(web_corpus, removeWords, c(stopwords("german"), "(m/w)", "(w/m)",
"(b.a.)", "mehr…", "..", "../", "(m/f)", "()," , "aldi", "rewe", "obi", "süd",
"bauhaus", "netto", "group", "mytoys", "metro", "gernsheim", "cash", "carry", "toom",
"the", "and", "for", "our", "bonprix", "nord", "real", "müller", "globus", "diska",
"markt", "zalando", "2018", "2017/2018", "sucht", "edeka", "hornbach", "dass", "otto",
"company", "fachcentren", "berlin", "intersport", "germany", "0221", "elias", "gabi",
"angela", "kik", "barry", "daniela", "waltrop", "gmbh", "manufactum", "köln",
"ascdsc", "johannes", "rossmann", "försterling,", "isabelle", "warenhaus",
"gmbhregion"))
# Korpus auswerten
dtm_texts <- DocumentTermMatrix(web_corpus, control = list(stemming = F))
# Korpus-Wortlisten in tidytext-Format umwandeln
library(tidytext)
dtm_texts_tidy <- tidy(dtm_texts)
# Informationen über die Unternehmen hinzufügen
library(stringi)
dtm_texts_tidy$ID_Hauptunternehmen <- as.numeric(
stri_extract(dtm_texts_tidy$document, regex = "[^.]*"))
dtm_texts_tidy$ID_Einzelunternehmen <- (stri_extract(
dtm_texts_tidy$document, regex = "[^_]*"))
dtm_texts_tidy <- dtm_texts_tidy %>% inner_join(company_list %>%
select(ID_Hauptunternehmen, Hauptunternehmen) %>%
distinct(ID_Hauptunternehmen, Hauptunternehmen))
dtm_texts_tidy <- dtm_texts_tidy %>% inner_join(company_list %>%
select(ID_Einzelunternehmen, Einzelunternehmen) %>%
distinct(ID_Einzelunternehmen, Einzelunternehmen))
Text-Analyse
Zunächst wird eine Wordcloud zur Übersicht über die Worte erstellt, die im gesamten Korpus mehr als 2 mal vorkommen.
library(wordcloud2)
set.seed(7712)
dtm_texts_tidy %>% select(term, count) %>% filter(count > 2) %>%
wordcloud2(., fontFamily = "Times", color = "black")

In einem nächsten Schritt werden die Texte auf ihre Emotionalität hin untersucht.
Dies geschieht mit Hilfe des SentiWS Wortschatzes, der Schlüsselworten eine
Emotionalität von -1 für negative bis +1 für positive Worte zuordnet.
## Download SentiWS hier: http://wortschatz.uni-leipzig.de/de/download
## Quelle Vorbereitung Wortliste https://www.inwt-statistics.de/blog-artikel-lesen/text-mining-part-3-sentiment-analyse.html
# Vorbereiten
sent <- c(
# positive Wörter
readLines("SentiWS_v1.8c/SentiWS_v1.8c_Positive.txt",
encoding = "UTF-8"),
# negative Wörter
readLines("SentiWS_v1.8c/SentiWS_v1.8c_Negative.txt",
encoding = "UTF-8")
) %>% lapply(function(x) {
# Extrahieren der einzelnen Spalten
res <- strsplit(x, "\t", fixed = TRUE)[[1]]
return(data.frame(words = res[1], value = res[2],
stringsAsFactors = FALSE))
}) %>%
bind_rows %>%
mutate(words = gsub("\\|.*", "", words) %>% tolower,
value = as.numeric(value)) %>%
# manche Wörter kommen doppelt vor, hier nehmen wir den mittleren Wert
group_by(words) %>% summarise(value = mean(value)) %>% ungroup
# Mit unserem Wortkorpus vereinen
dtm_texts_tidy <- dplyr::left_join(x = dtm_texts_tidy, y = sent,
by = c("term" = "words"))
# Ergebnisse darstellen
sentiment_texts <- dtm_texts_tidy %>%
group_by(document, Einzelunternehmen, Hauptunternehmen) %>%
summarise(sentiment = mean(value, na.rm = T)) %>%
arrange(sentiment)
knitr::kable(sentiment_texts, format = "markdown")
| document | Einzelunternehmen | Hauptunternehmen | sentiment |
|---|---|---|---|
| 7.1_KiK.txt | KiK | Tengelmann Warenhandelsgesellschaft | 0.0040000 |
| 1.2_Kaufland.txt | Kaufland | Schwarz Gruppe | 0.0217400 |
| 5.4_Toom.txt | Toom | Rewe Gruppe | 0.0303045 |
| 5.1_Rewe.txt | Rewe | Rewe Gruppe | 0.0338438 |
| 6.5_Frankonia.txt | Frankonia | Otto Gruppe | 0.0371200 |
| 4.1_Edeka-Verbund.txt | Edeka-Verbund | Edeka Gruppe | 0.0393625 |
| 3.1_Metro Cash and Carry.txt | METRO Cash & Carry | Metro AG | 0.0438091 |
| 4.5_Netto Marken-Discount.txt | Netto Marken-Discount | Edeka Gruppe | 0.0547536 |
| 4.3_Treff3000.txt | Treff3000 | Edeka Gruppe | 0.0579500 |
| 4.4_NP.Discount.txt | NP.Discount | Edeka Gruppe | 0.0617000 |
| 5.2_Penny.txt | Penny | Rewe Gruppe | 0.0673750 |
| 2.2_Aldi Süd.txt | Aldi Süd | Aldi Gruppe | 0.0691900 |
| 2.1_Aldi Nord.txt | Aldi Nord | Aldi Gruppe | 0.0698000 |
| 7.2_OBI.txt | OBI | Tengelmann Warenhandelsgesellschaft | 0.0759565 |
| 16.1_Zalando.txt | Zalando | Zalando SE | 0.0783435 |
| 4.2_Diska.txt | Diska | Edeka Gruppe | 0.0794250 |
| 17.1_Intersport.txt | INTERSPORT | Intersport Deutschland SE | 0.0845786 |
| 1.1_Lidl.txt | Lidl | Schwarz Gruppe | 0.0859882 |
| 9.1_Rossmann.txt | Rossmann | Dirk Rossmann GmbH | 0.0945375 |
| 15.1_Hornbach.txt | Hornbach | HORNBACH Baumarkt | 0.0952947 |
| 8.1_dm.txt | dm | dm-drogerie markt GmbH | 0.0960385 |
| 5.3_Nahkauf.txt | Nahkauf | Rewe Gruppe | 0.0977500 |
| 11.1_BAUHAUS.txt | BAUHAUS | BAUHAUS GmbH | 0.1059600 |
| 10.1_Globus.txt | Globus | Globus Holding GmbH | 0.1146913 |
| 12.1_Deichmann.txt | Deichmann | Deichmann SE | 0.1164455 |
| 6.6_SportScheck.txt | SportScheck | Otto Gruppe | 0.1193833 |
| 3.2_Real.txt | Real | Metro AG | 0.1201692 |
| 13.1_Müller.txt | Müller | Müller Holding | 0.1202969 |
| 6.3_myToys.txt | myToys | Otto Gruppe | 0.1261353 |
| 6.2_Manufactum.txt | Manufactum | Otto Gruppe | 0.1339591 |
| 6.4_BonPrix.txt | BonPrix | Otto Gruppe | 0.1770605 |
Dies lässt sich auch graphisch, geordnet nach Haupt- und Einzelunternehmen darstellen.
library(ggrepel)
ggplot(sentiment_texts, aes(x = reorder(Hauptunternehmen, -sentiment), y = sentiment)) +
theme_minimal(base_size = 28) + xlab("Unternehmensgruppe") + ylab("mean sentiment") +
coord_flip() +
geom_point(aes(x = Hauptunternehmen, y = sentiment), size = 8) +
geom_label_repel(aes(label = Einzelunternehmen), box.padding = unit(0.35, "lines"),
point.padding = unit(0.5, "lines"), size = 8)
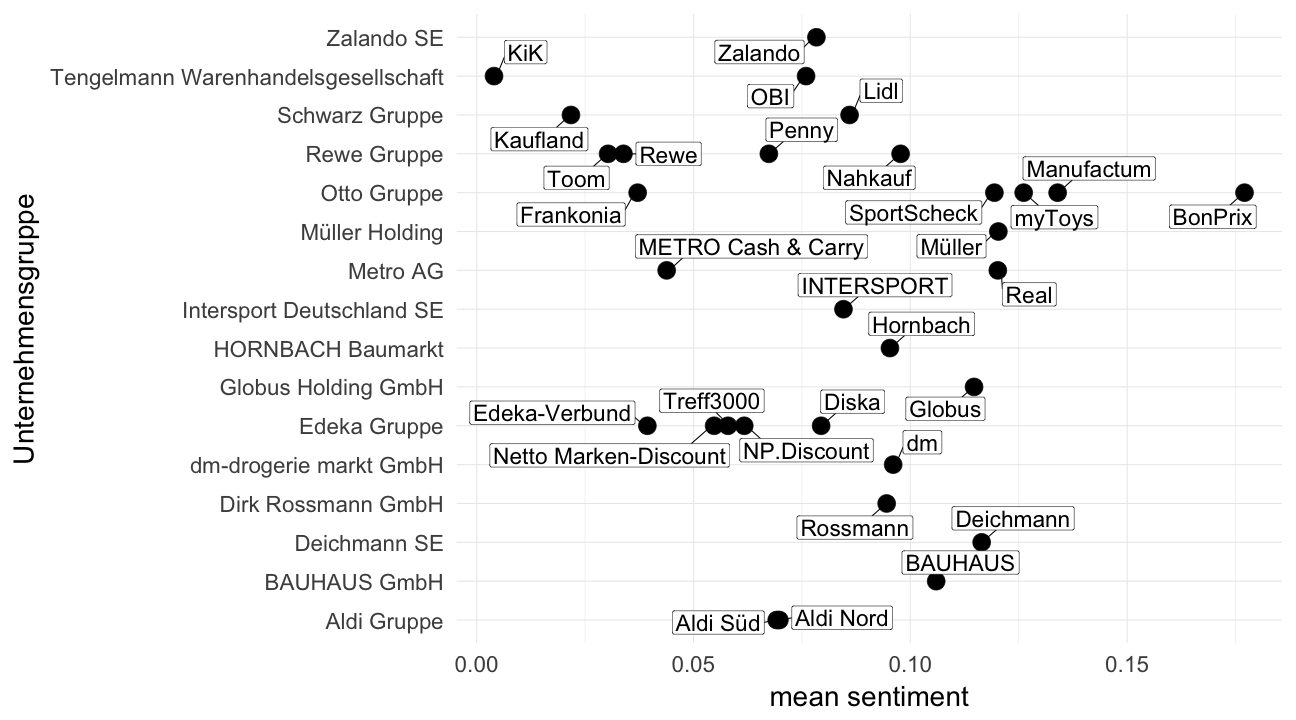
Und noch eine kleine Untersuchung, was die Top 5 positiven und negativen Worte in den einzelnen Texten nach Hauptunternehmen sind.
dtm_texts_tidy %>% group_by(Hauptunternehmen) %>%
top_n(5, value) %>%
ggplot(aes(x = reorder(term, value), y = value, group = Hauptunternehmen)) +
geom_col() + coord_flip() + theme_minimal(base_size = 22) + xlab("") +
ylab("sentiment") +
facet_wrap( ~ Hauptunternehmen, ncol = 4, scales = "free")
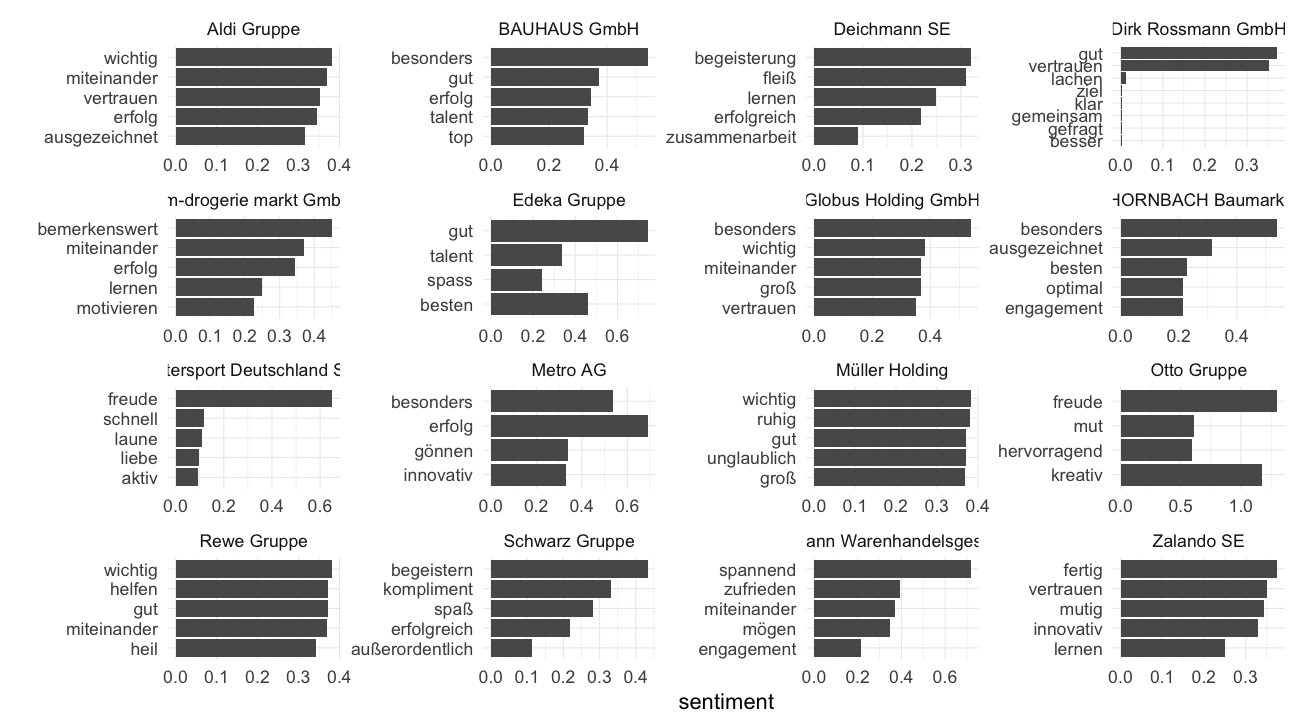
dtm_texts_tidy %>% group_by(Hauptunternehmen) %>%
filter(value < 0.1) %>%
top_n(-3, value) %>%
ggplot(aes(x = reorder(term, value), y = value, group = Hauptunternehmen)) +
geom_col() + coord_flip() + theme_minimal() + xlab("") + ylab("sentiment") +
facet_wrap( ~ Hauptunternehmen, ncol = 4, scales = "free")

Bild-Analyse
Wie sieht es mit der Bildsprache der Karriereseiten aus? Um die vorhandenen Bilder zu sammeln, werden die Karriere-Webseiten komplett heruntergeladen und die Bild-URLs extrahiert, um sie später analysieren lassen zu können. Etwas Nachbearbeitung ist leider manuell noch nötig.
library(rvest)
library(urltools)
# Leere Zeilen entfernen
company_list <- company_list %>% filter(Archiv.URL != "")
# Loop zum Suchen und Sammeln der Bild-URLs
image_urls_raw <- list()
for(i in 1:nrow(company_list)) {
name <- company_list[i, 4]
html_content <- read_html(company_list[i, 5])
img_urls <- html_content %>% html_nodes("img") %>% html_attr("src")
image_urls_raw[[name]] <- img_urls
}
# Manuelles Bearbeiten der Bild-URLs, wo nötig
image_urls_raw[["Lidl"]] <- paste0("https://", domain(company_list[1, 5]), image_urls_raw[["Lidl"]])
image_urls_raw[["Aldi Nord"]] <- paste0("https://", domain(company_list[3, 5]), "/karriere/", image_urls_raw[["Aldi Nord"]])
image_urls_raw[["Aldi Süd"]] <- paste0("https://", domain(company_list[4, 5]), image_urls_raw[["Aldi Süd"]])
image_urls_raw[["METRO Cash & Carry"]] <- paste0("https://", domain(company_list[5, 5]), image_urls_raw[["METRO Cash & Carry"]])
image_urls_raw[["Real"]] <- paste0("https://", domain(company_list[6, 5]), "/", image_urls_raw[["Real"]])
image_urls_raw[["Edeka-Verbund"]] <- paste0("https://", domain(company_list[7, 5]), image_urls_raw[["Edeka-Verbund"]])
image_urls_raw[["Diska"]] <- gsub("..", "", paste0("https://", domain(company_list[8, 5]), image_urls_raw[["Diska"]]), fixed = T)
image_urls_raw[["NP.Discount"]] <- paste0("https://", domain(company_list[10, 5]), "/", image_urls_raw[["NP.Discount"]])
image_urls_raw[["Rewe"]] <- paste0("https://", domain(company_list[12, 5]), image_urls_raw[["Rewe"]])
image_urls_raw[["Penny"]] <- paste0("https://", domain(company_list[13, 5]), image_urls_raw[["Penny"]])
image_urls_raw[["Nahkauf"]] <- paste0("https://", domain(company_list[14, 5]), image_urls_raw[["Nahkauf"]])
image_urls_raw[["Toom"]] <- paste0("https://", domain(company_list[15, 5]), image_urls_raw[["Toom"]])
image_urls_raw[["Frankonia"]] <- paste0("https://", domain(company_list[19, 5]), image_urls_raw[["Frankonia"]])
image_urls_raw[["OBI"]] <- gsub("../", "", paste0("https://", domain(company_list[22, 5]), "/karriere/", image_urls_raw[["OBI"]]), fixed = T)
image_urls_raw[["Globus"]] <- paste0("https://", domain(company_list[25, 5]), image_urls_raw[["Globus"]])
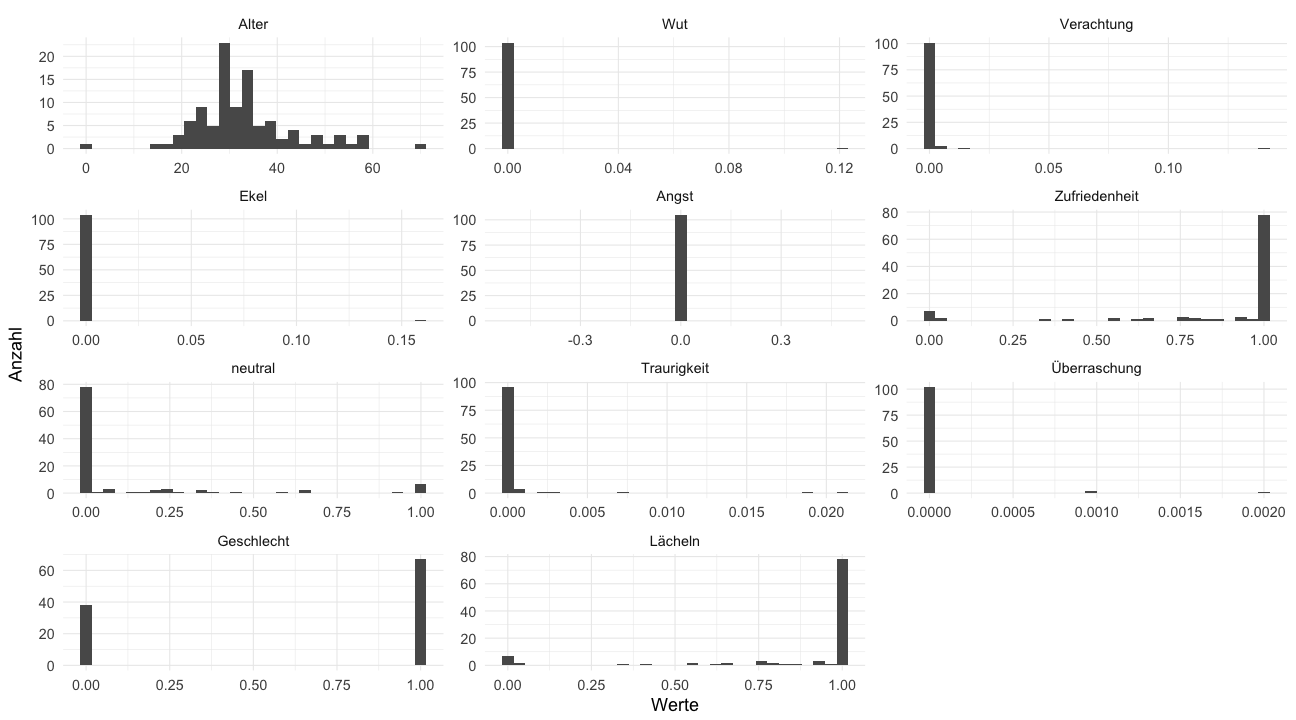
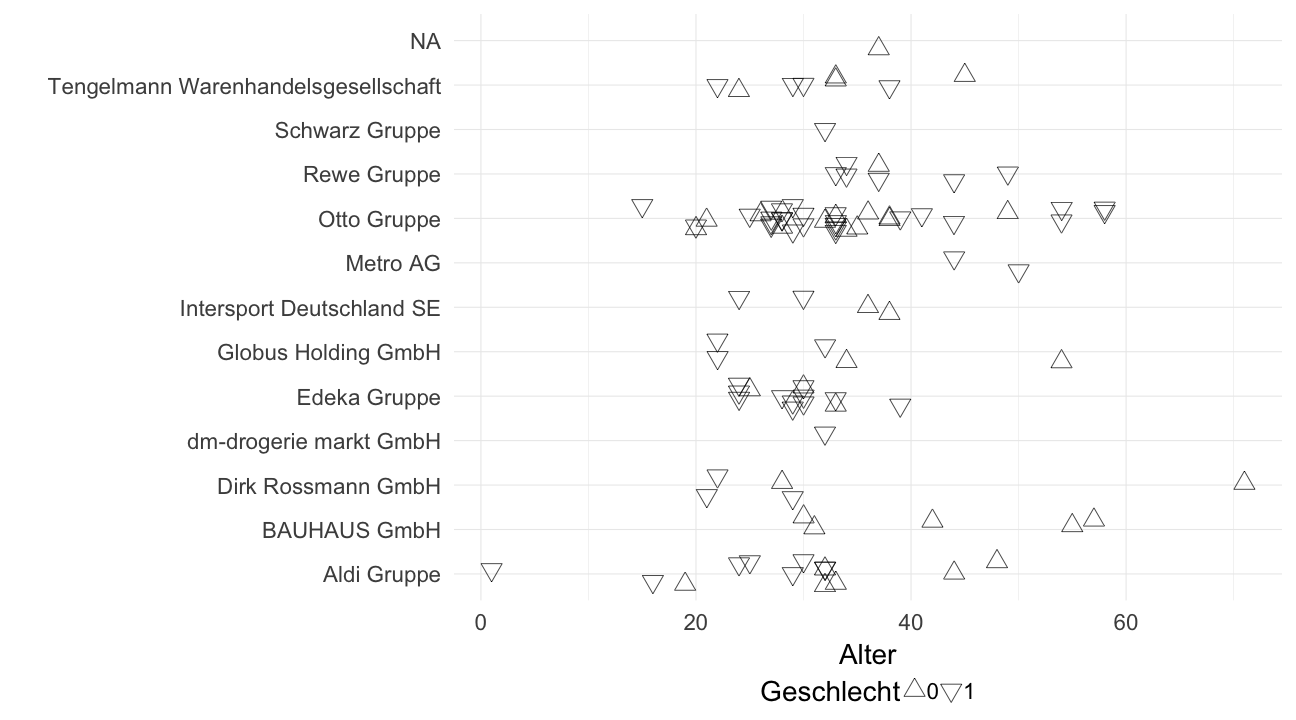
Im nächsten Schritt werden die gesammelten Bilder durch den Dienst Microsoft Azure Face API untersucht.
Die KI liefert dann Ergebnisse zu den erkannten Gesichtern zurück, z.B. das Alter und Geschlecht.
# in Anlehnung an https://bigdataenthusiast.wordpress.com/2016/10/17/face-api-microsoft-cognitive-services/
# Unternehmensnamen und URLs zusammenführen
urls_df <- data.frame(company = NA, url = NA)
for (i in 1:length(image_urls_raw)) {
for(j in 1:length(image_urls_raw[[i]])){
df <- data.frame(company = names(image_urls_raw[i]), url = image_urls_raw[[i]][j])
urls_df <- dplyr::bind_rows(urls_df, df)
}
}
urls_df <- na.omit(urls_df)
# Azure Face API einbinden
library(httr)
face_api_url = "https://westeurope.api.cognitive.microsoft.com/face/v1.0/detect?returnFaceId=true&returnFaceLandmarks=false&returnFaceAttributes=age,gender,smile,emotion,makeup"
api_results_list <- list()
# Achtung!
# Hier muss der eigene "Ocp-Apim-Subscription-Key" Wert eingetragen werden.
# Dazu ist ein Azure-Konto anzulegen :-)
for (i in 1:nrow(urls_df)) {
url <- urls_df[i,2]
api_url_generator <- paste0("{'url':'", url, "'}")
result = POST(face_api_url,
body = api_url_generator,
add_headers(.headers = c("Content-Type" = "application/json",
"Ocp-Apim-Subscription-Key" = "DEIN_SCHLÜSSEL")))
nameing <- paste0(urls_df[i,1], "##", i)
res <- content(result)
api_results_list[[nameing]] <- res
Sys.sleep(0.3)
}
## In Datensatz konvertieren
api_results_df <- data.frame()
for (i in 1:length(api_results_list)) {
for (j in length(api_results_list[[i]])) {
df <- (as.data.frame(api_results_list[[i]][j]))
if (length(df) > 0) {
df$name <- names(api_results_list[i])
api_results_df <- dplyr::bind_rows(api_results_df, df)
}
}
}
## In einem neuen Datensatz zusammenführen
face_data <- api_results_df %>% filter(!is.na(faceId))
face_data$company_name <- sub("##.*", "", face_data$name)
Die Daten lassen sich nun auch graphisch auswerten.
face_data$faceAttributes.gender_num[face_data$faceAttributes.gender == "male"] <- 0
face_data$faceAttributes.gender_num[face_data$faceAttributes.gender == "female"] <- 1
labels <- c(faceAttributes.age = "Alter",
faceAttributes.smile = "Lächeln",
faceAttributes.gender_num = "Geschlecht",
faceAttributes.emotion.anger = "Wut",
faceAttributes.emotion.contempt = "Verachtung",
faceAttributes.emotion.disgust = "Ekel",
faceAttributes.emotion.fear = "Angst",
faceAttributes.emotion.happiness = "Zufriedenheit",
faceAttributes.emotion.neutral = "neutral",
faceAttributes.emotion.sadness = "Traurigkeit",
faceAttributes.emotion.sadness = "Traurigkeit",
faceAttributes.emotion.surprise = "Überraschung"
)
face_data <- left_join(x = face_data, y = company_list,
by = c("company_name" = "Einzelunternehmen"))
face_data %>%
keep(is.numeric) %>%
select(-faceRectangle.height, -faceRectangle.left, -faceRectangle.top,
-faceRectangle.width, -starts_with("ID_Haupt")) %>% na.omit() %>%
gather() %>%
ggplot(aes(value)) +
facet_wrap(~ key, scales = "free", nrow = 4, labeller = labeller(key = labels)) +
geom_histogram() + theme_minimal(base_size = 18) + ylab("Anzahl") + xlab("Werte")
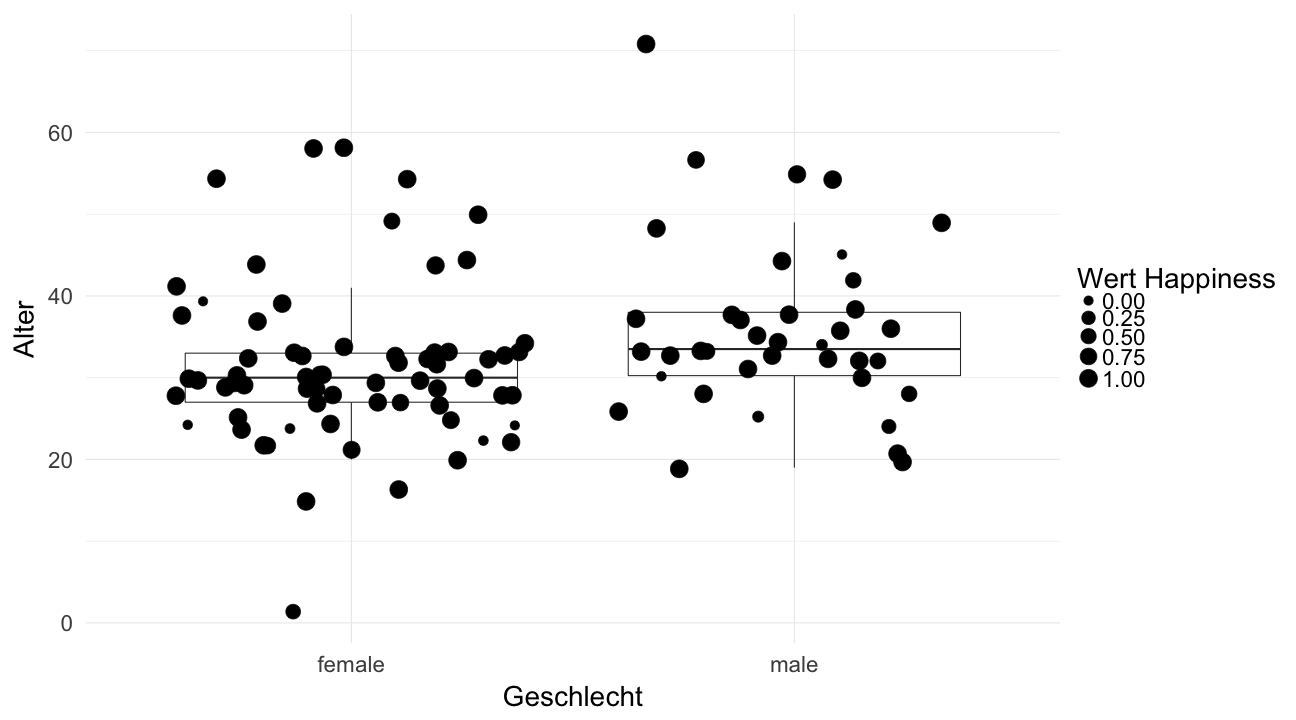
ggplot(data = face_data, aes(x = faceAttributes.gender, faceAttributes.age)) +
geom_boxplot(outlier.shape = NA) +
geom_jitter(aes(size = faceAttributes.emotion.happiness)) +
theme_minimal(base_size = 28) +
xlab("Geschlecht") + ylab("Alter") +
scale_size_continuous(name="Wert Happiness", range = c(4, 8))
face_data %>% group_by(Hauptunternehmen) %>%
ggplot(aes(x = Hauptunternehmen, y = faceAttributes.age,
shape = as.factor(faceAttributes.gender_num))) +
geom_jitter(height = 0.01, width = 0.3, size = 7) + coord_flip() +
theme_minimal(base_size = 28) +
xlab("") + ylab("Alter") + scale_shape_manual(name="Geschlecht", values = c(2, 6)) +
theme(legend.position="bottom")
Kommentare oder Fragen?
Ich freue mich auf Kommentare und Fragen. Eine detailliertere Auswertung und Interpretation findet sich dann im bald erscheinenden Sammelband.